While learning how to create Hugging Face “Spaces”, I ran across a wonderful getting-started guide in the Hugging Face documentation. It walks new users through creating a Space that can classify images into “Hotdog” or “Not Hotdog”.
It reminded me a little bit of this Penny Arcade from many years back, which features a “Pickle Recognition Engine”.
Getting the Space set up was really easy, maybe a 5 minute task. I immediately set about trying to break it. I started things off with an easy image:
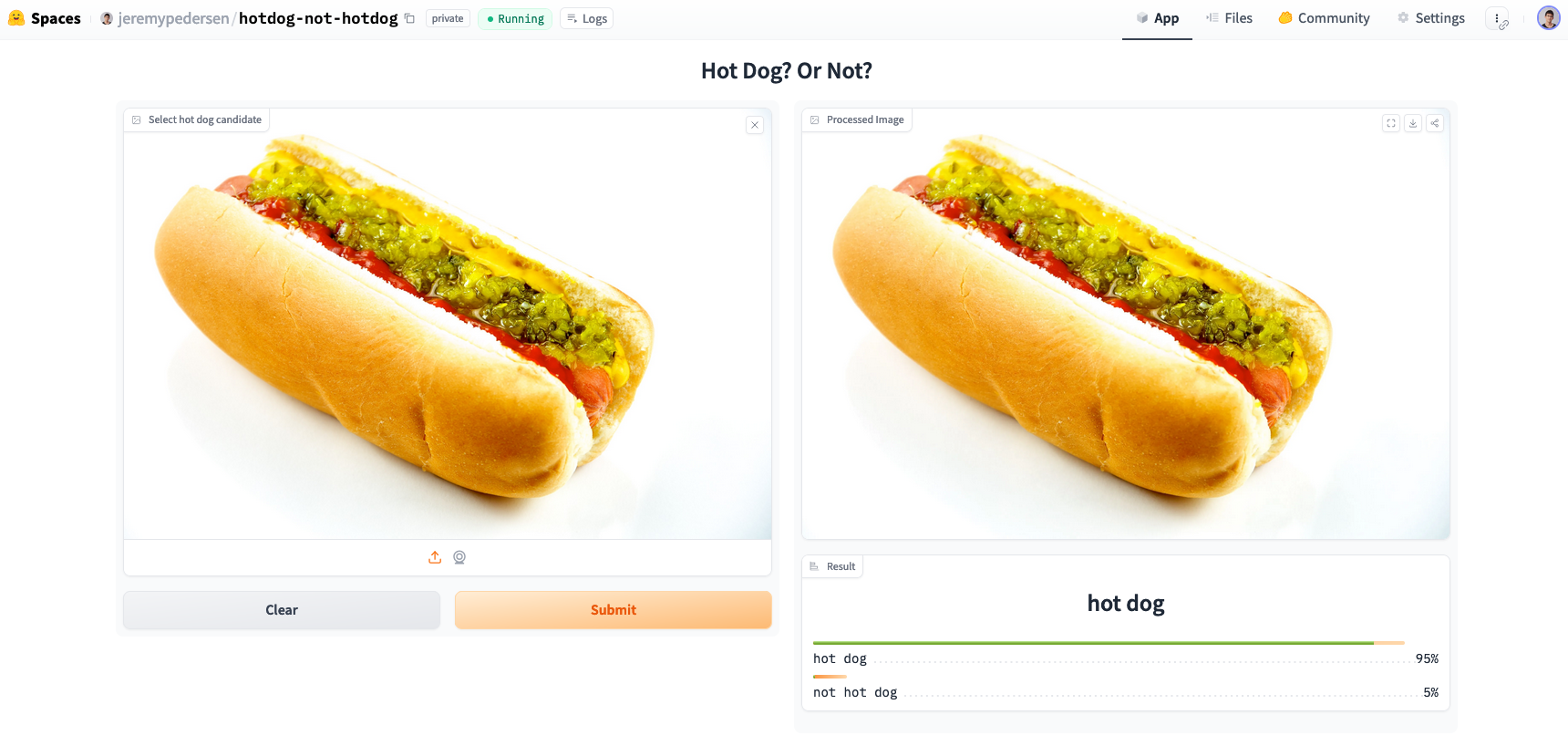
No problems whatsoever correctly identifying the hotdog. What about a dog that kinda looks like a hotdog? Time to try a photo of the trusty Dachshund:
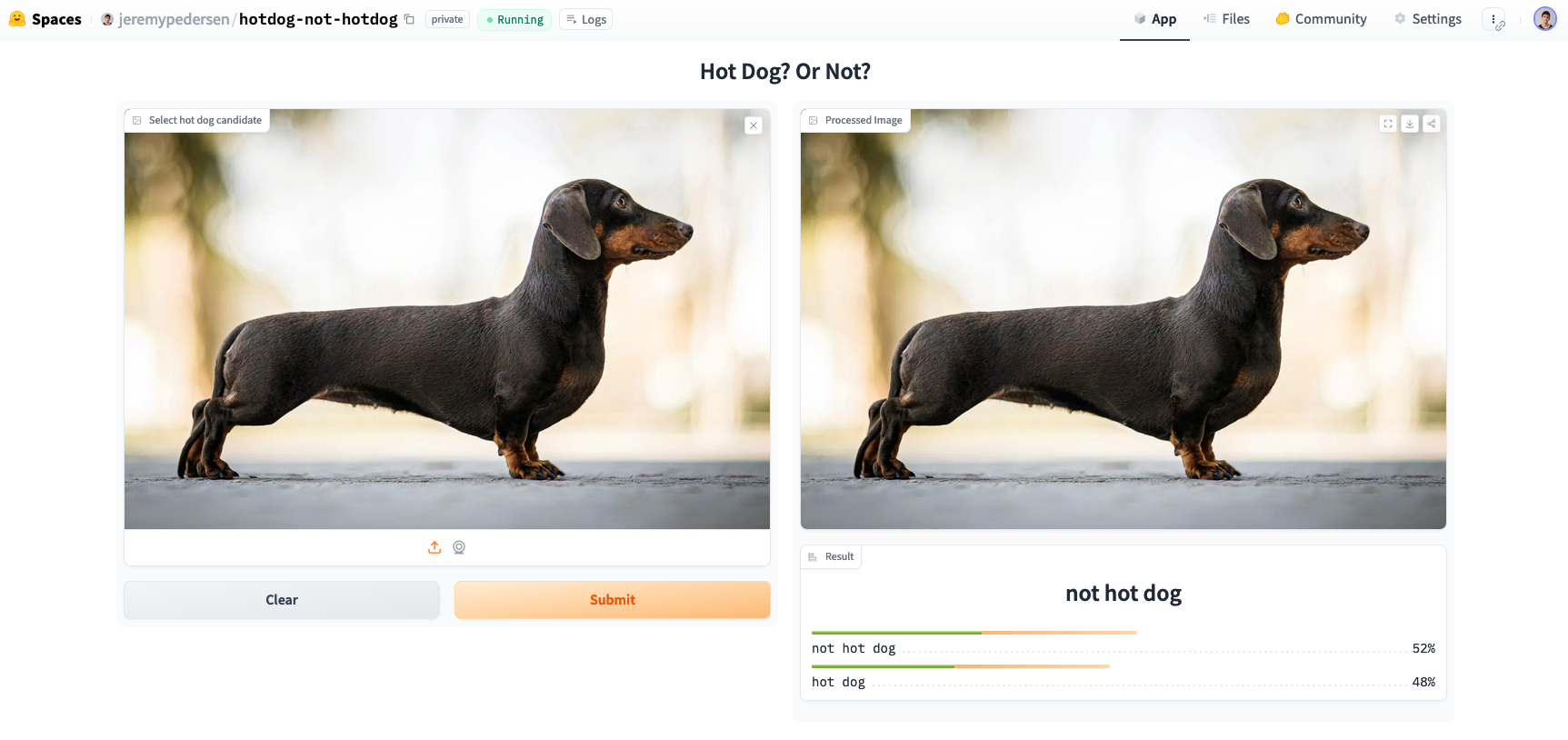
Sure enough, the model had a little more difficulty with this one. It got the right answer, but it was a close call. So what about a Dachshund dressed as a hotdog? A quick google search netted a surprising number of results. I went with this one:
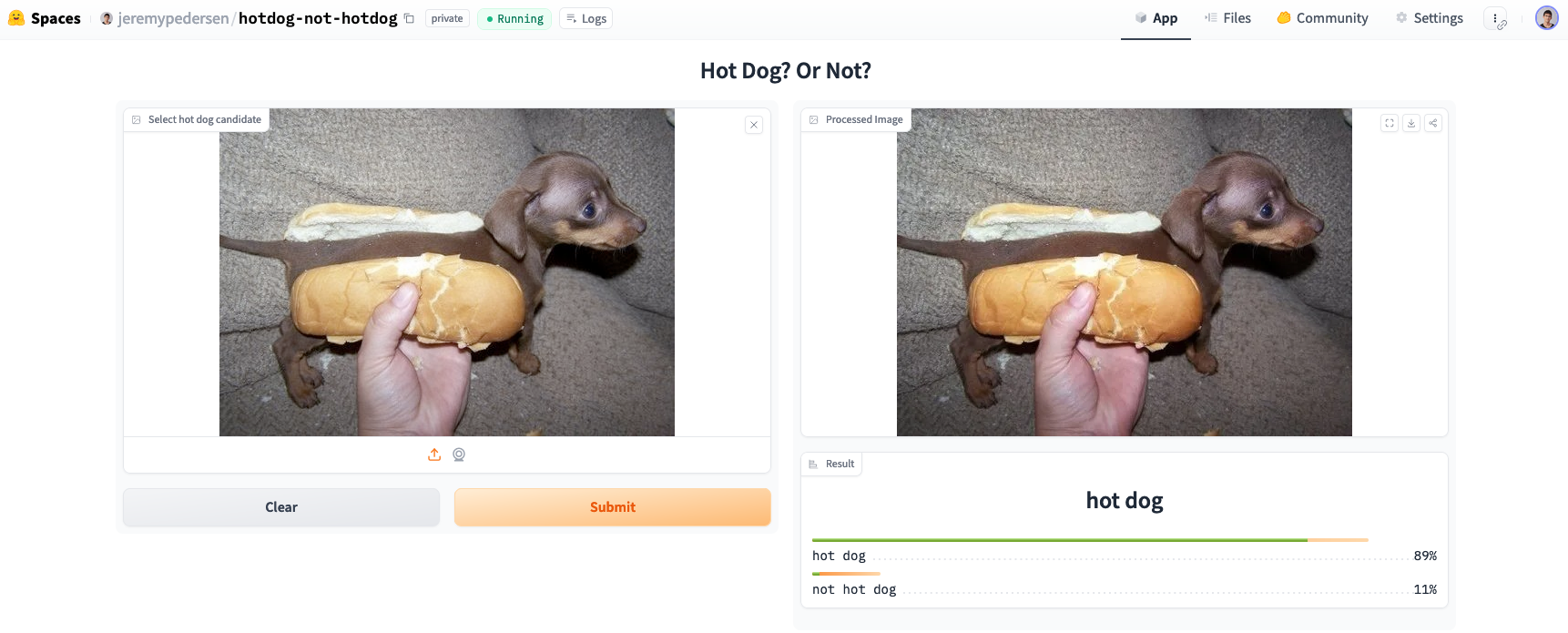
Ah, there it is.
But why does this image trick a machine learning model so easily? Even a toddler could correctly identify the adorable doggie here.
This got me thinking about AI and “edge cases”. I think there are a couple of things going on in this image that make it especially challenging for the model to deal with:
- Unusual scale
- Unusual pose
- Unusual combination of features
Unusual scale Link to heading
The Dachshund here is a puppy, and is so small that it can fit easily into a person’s hand (or a hotdog bun), just like an actual hotdog.
If the model is able to use any context clues in the image to work out scale, it may be biased towards classifying the image as a hotdog because the subject of the image is roughly the size of a hotdog.
Unusual pose Link to heading
To add to the comedy value of the image, the photographer has placed their hand under the dog in a sort of “pincers” grip, similar to the way people typically hold a hotdog, and very unlike the way in which people typically hold dogs.
Unusual combination of features Link to heading
The Dachshund here has been placed inside an actual hotdog bun. It’s unlikely that the model’s training set included many examples of “dogs dressed as hotdogs”. The presence of a bun (and a human hand) likely creates a strong bias towards classifying the image as a hotdog.
Takeaways Link to heading
1. Test and train with synthetic data, not just real data Link to heading
To get a really accurate classifier, it’s important to consider how key features might be combined in unexpected ways. Intentionally including synthetic data that tries to emulate real world “edge cases” is (probably) a good way to stress test classifiers.
In the case of image classifiers, we now have a superweapon that makes this type of data augmentation much easier: text-to-image models. A model like FLUX.1 is easily good enough to understand a prompt like “dog dressed as a hotdog”. Here’s the first image it generated when I asked:

2. Be prepared to iterate Link to heading
It’s impossible to enumerate all your edge cases up front, but you’ll “know ’em when you see ’em”. So be prepared to go back and re-train or update your models constantly. Setting up a framework or pipeline to make this easy to do is a key consideration. “One and done” training of models might be fine for a proof-of-concept, but won’t work in production.